To aid us with this, we can take advantage of a number of system stored procedures that come with SQL Server.
- SP_HELPDB
- Returns basic and extended information about a database, depending on if the database name is passed as a parameter
- SP_HELPFILE
- Returns information about the physical files associated with the database
- SP_SPACEUSED
- Returns information about a table. This includes rows, disk space, index sizes, etc.
- SP_MSFOREACHTABLE
- This is an undocumented stored procedure that allows you to execute a statement against every table in a database
For database information we can execute an SQL statement like this(The temp tables can be replaced with tables used for staging data):
-->DECLARATIONS
-->HOLDS DATABASE NAMES
DECLARE @TEMP_DB_NAME TABLE
(
DB_KEY INT IDENTITY(1,1),
DB_NAME VARCHAR(200)
)
-->HOLDS THE NUMBER OF DATABASES TO LOOP FOR
DECLARE @NUMBER_DBS INT
-->ITERATOR
DECLARE @COUNTER INT
-->DB NAME IN LOOP
DECLARE @DB_NAME VARCHAR(200)
-->HOLD EXECUTE STATEMENT
DECLARE @STATEMENT VARCHAR(200)
-->LOADS THE TEMP TABLE WITH OUR DATABASE NAMES
INSERT INTO @TEMP_DB_NAME
SELECT
NAME
FROM
SYS.DATABASES
WHERE
DATABASE_ID>4
AND HAS_DBACCESS(NAME)=1
-->INITIALIZE ITERATOR
SET @COUNTER=1
-->SETS THE NUMBER OF DATABASES WE HAVE
SELECT
@NUMBER_DBS=MAX(DB_KEY)
FROM
@TEMP_DB_NAME
CREATE TABLE #DATABASEINFO
(
NAME VARCHAR(128),
DB_SIZE NVARCHAR(13),
OWNER VARCHAR(255),
DBID SMALLINT,
CREATED SMALLDATETIME,
STATUS NVARCHAR(600),
COMPATIBILITY_LEVEL TINYINT,
PROCESSDATE DATETIME
)
-->EXTENDED DATABASE INFO
CREATE TABLE #DATABASEEXTINFO
(
NAME VARCHAR(128),
FILEID SMALLINT,
FILENAME NCHAR(260),
FILEGROUP NVARCHAR(128),
DBSIZE NVARCHAR(18),
MAXDBSIZE NVARCHAR(18),
GROWTH NVARCHAR(18),
USAGE VARCHAR(9),
DATABASENAME VARCHAR(128),
PROCESSDATE DATETIME
)
-->LOOP
WHILE @COUNTER<= @NUMBER_DBS
BEGIN
SELECT
@DB_NAME = DB_NAME
FROM
@TEMP_DB_NAME
WHERE
DB_KEY=@COUNTER
-->GET EXTENDED INFORMATION
EXEC('USE '+ @DB_NAME + ' INSERT INTO #DATABASEEXTINFO (NAME, FILEID, FILENAME, FILEGROUP, DBSIZE, MAXDBSIZE, GROWTH, USAGE)
EXEC SP_HELPFILE')
UPDATE
#DATABASEEXTINFO
SET
DATABASENAME=@DB_NAME
WHERE
DATABASENAME IS NULL
SET @COUNTER= @COUNTER+1
END
-->ALL DATABASE GENERAL INFO
INSERT INTO #DATABASEINFO (NAME, DB_SIZE, OWNER, DBID, CREATED, STATUS, COMPATIBILITY_LEVEL)
EXEC SP_HELPDB
-->REMOVE SYSTEM DATABASES
DELETE FROM #DATABASEINFO WHERE DBID<5
-->SET PROCESSEDATE
UPDATE #DATABASEINFO SET PROCESSDATE=GETDATE()
UPDATE #DATABASEEXTINFO SET PROCESSDATE=GETDATE()
-->SHOW RESULTS
SELECT
NAME,
DB_SIZE,
OWNER,
DBID,
CREATED,
STATUS,
COMPATIBILITY_LEVEL,
PROCESSDATE
FROM
#DATABASEINFO
SELECT
NAME,
FILEID,
FILENAME,
FILEGROUP,
DBSIZE,
MAXDBSIZE,
GROWTH,
USAGE,
DATABASENAME,
PROCESSDATE
FROM
#DATABASEEXTINFO
-->DROP TEMP TABLES
DROP TABLE #DATABASEEXTINFO
DROP TABLE #DATABASEINFO
This statement will produce 2 recordsets (tuples) that look something like this:
 |
| Figure 1. SP_HELP with No Parameter |
 |
| Figure 2. SP_HELP with Database Name Parameter |
These 2 data sources can then be used to generate the tables behind this schema:
 |
| Figure 3. Database Growth Schema |
This schema represents a periodic snapshot that captures the database file and log file sizes daily. You sum on FILE_SIZE and roll up to the database to get the size of the entire database on a given day. If you have all of your inserts and updates for the entire database logged in another table, you can roll those up to the database/day level and add those as measures to the fact as well. From this schema you could produce daily database reports giving an overview of what the growth looks like:
 |
| Figure 4. Database Growth Report |
To get down to the level of granularity of individual tables, we can execute a SQL statement similar to this (The temp tables can be replaced with tables used for staging data):
-->DECLARATIONS
-->HOLDS DATABASES TO LOOP THROUGH
DECLARE @TEMP_DB_NAME TABLE
(
DB_KEY INT IDENTITY(1,1),
DB_NAME VARCHAR(200)
)
-->HOLDS DATA ABOUT EACH TABLE
CREATE TABLE #TABLEINFO (
NAME VARCHAR(200),
ROWS INT,
RESERVED VARCHAR(255),
DATA VARCHAR(20),
INDEX_SIZE VARCHAR(20),
UNUSED VARCHAR(250),
DBNAME VARCHAR(50),
PROCESSDATE DATETIME
)
-->HOLDS THE NUMBER OF DATABASES TO LOOP FOR
DECLARE @NUMBER_DBS INT
-->ITERATOR
DECLARE @COUNTER INT
-->DB NAME IN LOOP
DECLARE @DB_NAME VARCHAR(200)
-->LOADS THE TEMP TABLE WITH OUR DATABASE NAMES
INSERT INTO @TEMP_DB_NAME
SELECT
NAME
FROM
SYS.DATABASES
WHERE
DATABASE_ID>4
AND HAS_DBACCESS(NAME)=1
-->INITIALIZE ITERATOR
SET @COUNTER=1
-->SETS THE NUMBER OF DATABASES WE HAVE
SELECT
@NUMBER_DBS=MAX(DB_KEY)
FROM
@TEMP_DB_NAME
-->PERFORMS AN INSERT OF TABLE STATS FOR EACH DATABASE
WHILE @COUNTER<= @NUMBER_DBS
BEGIN
SELECT
@DB_NAME = DB_NAME
FROM
@TEMP_DB_NAME
WHERE
DB_KEY=@COUNTER
-->GET TABLE STATISTICS
EXECUTE(
'USE '+@DB_NAME +
' INSERT INTO #TABLEINFO
(
NAME,
ROWS,
RESERVED,
DATA,
INDEX_SIZE,
UNUSED
)
EXEC SP_MSFOREACHTABLE @COMMAND1="EXEC SP_SPACEUSED ''?''"')
UPDATE A
SET
A.DBNAME=@DB_NAME,
A.PROCESSDATE=GETDATE()
FROM
#TABLEINFO A
WHERE
A.DBNAME IS NULL
AND A.PROCESSDATE IS NULL
SET @COUNTER= @COUNTER+1
END
-->SELECT TABLE STATS
SELECT
NAME,
ROWS,
replace(RESERVED,'KB','') as RESERVED,
replace(DATA, 'KB','') as DATA,
replace(INDEX_SIZE,'KB','') as INDEX_SIZE,
replace(UNUSED,'KB','') as UNUSED,
DBNAME,
PROCESSDATE
FROM
#TABLEINFO
WHERE
NAME<>'SYSDIAGRAMS'
-->DROP OUR TEMP TABLE
DROP TABLE #TABLEINFO
This statement will produce the following recordset:
 |
| Figure 5. SP_SPACEUSED |
From this data source we can derive a schema that looks something like this:
 |
| Figure 6. Table Growth Schema |
This schema represents a periodic snapshot that captures the table growth daily. If you have all of your inserts and updates for the each table logged, you can roll those up to the table/database/day level and add those as measures to the fact as well. From this schema you could produce daily table reports giving an overview of what the growth looks like:
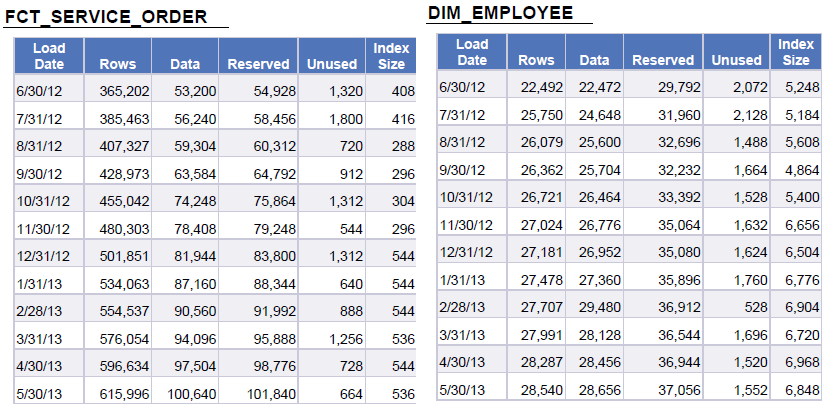 |
| Figure 7. Table Growth Report |
These 4 system stored procedures give us a good place to start from in recording database metrics that pertain to scalability. The sky is basically the limit for how much you want to log, but this is a pretty good example of how simple it is to achieve.






